I förra veckan publicerade Johan Martinsson från Göteborgs universitet ett inlägg på bloggen Politologerna (där för övrigt även jag skriver ibland) kring jämförelser mellan olika undersökningar, bland annat webbpaneler. Inlägget väckte intresse bland olika personer som intresserar sig för opinionsmätningar, inte minst då det på vissa håll tolkades som om resultatet av jämförelsen var att självrekryterade webbpaneler är bättre än traditionella undersökningar, se exempelvis Lena Mellin i Aftonbladet. Även Dagens Opinion framförde något liknande, men där var missförståndet än större då journalisten verkade tro att det var Politologerna som genomfört en undersökning. Det kan därför vara värt att understryka att så inte är fallet och även att Politologerna är en blogg där respektive skribent står för sina egna inlägg. I vilket fall, då jag upplever att diskussionen har hamnat lite snett tänkte jag, måhända naivt, försöka ge min syn på saken i hopp om att något kanske blir lite klarare för någon.
Först och främst tycker jag att det är väldigt bra att Johan och andra intresserar sig för frågan om webbpaneler och vilken kvalitet de har (se även Novus jämförelse här). I USA och en del andra länder är intresset för sådana metodfrågor betydligt större än i Sverige, men förhoppningsvis kan frågorna få större uppmärksamhet även här. Innan jag går in på undersökningen vill jag beröra något som ofta missförstås: att samla in data via webben är bara en annan insamlingsform (eller mode som man säger på engelska). Beroende på om man samlar in data via besöksintervju, telefonintervju, postenkät eller webbenkät kan det ha vissa effekter på inflöde och hur folk svarar. Men i princip behöver inte webbenkäter skilja sig på andra sätt, som exempelvis urvalsdesign. Däremot är det ofta svårt att dra ett slumpmässigt så kallat sannolikhetsurval (där alla som ingår i populationen har en känd sannolikhet att bli utvalda och den sannolikheten är större än noll) och sedan kontakta personer direkt i elektronisk form. Detta då vi inte har något centralt register över e-postadresser (något som inte vore dumt att ha!). Webbundersökningar har därför ofta blivit synonyma med icke-slumpmässiga urval, så kallade självrekryterade urval, men så behöver alltså inte vara fallet.
I sitt blogginlägg jämför Johan sju olika undersökningar: tre som baseras på slumpmässiga befolkningsurval och insamlat medelst telefon, postenkät respektive webbenkät, två slumpmässigt rekryterade webbpaneler och två självrekryterade webbpaneler. Det är med andra ord både en blandning av insamlingsmetoder och urvalsmetoder som studeras. Sedan jämförs hur de svarande i de olika undersökningarna fördelar sig efter några kända fördelningar vad gäller kön, ålder, utbildningsnivå, arbetslöshet och körkortsinnehav. Avsikten är att även analysera skillnader efter åsikter och samband mellan dessa två aspekter. Dessa två senare delar ingår dock inte i blogginlägget, även om det finns några deskriptiva redovisningar i den tillhörande tabellbilagan (och jag antar att de kommer i någon senare rapport).
Jämförelsen görs genom att genomsnittliga avvikelser i procentenheter räknas fram. Man kan diskutera metoden (man bör egentligen förhålla sig till nivån på det som ska skattas osv.), men den känns igen från valtider. Då brukar opinionsinstitutens sista mätning jämföras med valresultatet och någon kommer fram till att ett var “bäst”, och det institutet brukar basunera ut resultatet. Jag kan förstå att det kan framkalla glädje, men för mig är själva tankesättet främmande. Om vi tar ett exempel som jag tidigare visat på Politologerna: en simulering av 20 olika undersökningar som under perfekta förhållanden (utan bortfall, mätfel, etc.) skattar andelen röster på Centerpartiet, vilket gav följande resultat (punkterna är skattningar, den vertikala linjen det sanna värdet, se tidigare inlägg för tolkning).
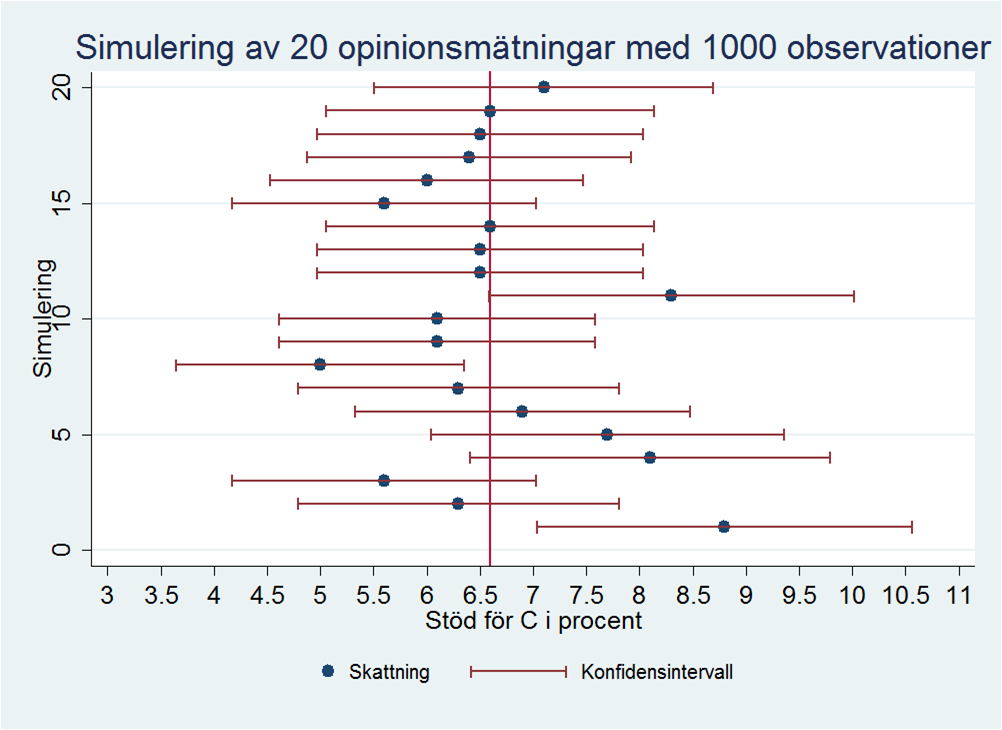
Dessa resultat skulle kunna komma från 20 olika undersökningar som genomförts på exakt samma sätt. Att påstå att något av dessa tänkta undersökningar skulle vara bättre är märkligt. Däremot är det klart att några _utfall _ligger närmare det sanna värdet, men det är en annan sak. Visst, _i genomsnitt _bör upprepade undersökningar ligga nära det sanna värdet, annars har man en bias (snedvridning av resultaten). En annan central kvalitetsaspekt som inte berörs i Johans inlägg gäller precisionen i undersökning, dvs. variansen. I bilden ovan illustreras den genom felmarginalerna tillhörande respektive skattning (de horisontella röda linjerna). Ibland tvingas man göra en avvägning mellan bias och precision, t.ex. genom att tillåta en viss bias i utbyte mot bättre precision. För att man ska kunna beräkna varianser krävs dock ett sannolikhetsurval (här kan man invända att alltför stora bortfall gör att man kan ifrågasätta om man verkligen har sannolikhetsurval, men det här inlägget börjar redan bli väldigt långt så jag får ta den diskussionen någon annan gång).
Så, med andra ord tycker jag inte att en jämförelse mellan ett utfall och sanna värden säger särskilt mycket. Men låt oss ändå titta på resultaten i Johans inlägg, då de som ovan nämnts har fått viss spridning. De fyra webbpaneler som ingår i jämförelserna har alla viktats. Det framgår inte hur de har viktats, förutom för Cint som har viktats efter kön och ålder, men troligen har de andra åtminstone viktats för samma egenskaper. Det blir då lite märkligt att sedan jämföra hur nära de kommer de sanna fördelningar efter samma variabler som de har viktats mot - föga förvånande kommer de nära. Visserligen presenteras även oviktade resultat, men då det inte framgår hur urvalen dragits för de självrekryterande urvalen säger det inte så mycket. Troligen är de utvalda med någon form av kvoturval där man har försökt få antalet svarande att likna någon fördelning. Om den fördelningen är kön och ålder är det naturligt om fördelningen också liknar den sanna fördelningen i dessa avseenden.
När det gäller övriga variabler, dvs. utbildning, arbetslöshet och körkortsinnehav, varierar det mer mellan de olika undersökningarna (och alla har inte information för alla variabler, vilket försvårar jämförelsen ytterligare). Exempelvis hamnar Cint snett för arbetslöshet, men nära i övriga två avseenden (se tabellbilagan). Det finns dock betydande problem med att mäta utbildning i form av högskoleexamen och arbetslöshet, där den officiella statistiken kan avvika med personers egen uppfattning. Detta är ett generellt problem och gäller inte bara den här jämförelsen: det är svårt att hitta relevant information att utvärdera träffsäkerhet och den man har tillgång till är sällan den som man vill mäta i undersökningen (i så fall skulle vi inte behöva göra studien). En ytterligare aspekt som inte tas upp i jämförelsen är att antalet svarspersoner skiljer mellan undersökningarna och precisionen hänger till stor del samman med antalet svarande.
Poängen här är dock att detta inte säger något om kvaliteten på undersökningarna. Det går inte att dra sådana slutsatser av ett utfall. Dessutom är en grundläggande förutsättning för att kunna göra en jämförelse att det finns information om hur personer väljs ut, hur stort det totala bortfallet är och hur estimationen går till. Allt detta saknas här. Med andra ord vet vi inte mycket mer nu än tidigare. Dessutom bör det åter understrykas att vid sannolikhetsurval kan vi skatta osäkerheten i våra estimat, vilket inte går om vi inte har ett sannolikhetsurval. Det är en relevant kvalitetsaspekt oavsett eventuell bias.
Jag instämmer dock i den slutsats som Johan landar i, dvs. vi behöver mer undersökningar kring detta. Förhoppningsvis kan hans studie i kombination med framtida undersökningar ge mer information i dessa frågor.