Att grafiskt åskådliggöra sina data är inte bara en möjlighet att underlätta för läsaren att förstå och tolka en undersöknings resultat. Det är inte konstigt att många inflytelserika forskare inom samhällsvetenskaperna, som Gary King och Andrew Gelman, på senare tid lyft fram vilket fantastiskt verktyg visualisering av data kan vara i dessa sammanhang (även om genomslaget än så länge varit ganska litet, i alla fall i Sverige). Grafiken kan även vara till stor hjälp vid analys av data. Vi har mycket lättare att snabbt ta till oss ett datamaterial som illustrerats grafiskt, och framför allt har vi en förmåga att urskilja mönster i grafer som går oss förbi ifall samma data skulle presenteras i tabellform.
Grafikens möjligheter i dessa sammanhang illustreras mycket tydligt genom Anscombes kvartett. Det är en kvartett dataset som blev kända genom Francis J Anscombes artikel “Graphs in Statistical Analysis” i The American Statistician, 1973. Artikeln är mycket läsvärd och den utgör en kraftfull argumentation för användandet av grafer i analys av datamaterial (frågan är om man i dag skulle komma undan med ett sådant språk i en vetenskaplig artikel). I artikeln presenterar Anscombe fyra dataset med värden för två variabler: x och y.
| **1 ** | **2 ** | **3 ** | ** 4** | ||||
| x | y | x | y | x | y | x | y |
| 10 | 8,04 | 10 | 9,14 | 10 | 7,46 | 8 | 6,58 |
| 8 | 6,95 | 8 | 8,14 | 8 | 6,77 | 8 | 5,76 |
| 13 | 7,58 | 13 | 8,74 | 13 | 12,74 | 8 | 7,71 |
| 9 | 8,81 | 9 | 8,77 | 9 | 7,11 | 8 | 8,84 |
| 11 | 8,33 | 11 | 9,26 | 11 | 7,81 | 8 | 8,47 |
| 14 | 9,96 | 14 | 8,1 | 14 | 8,84 | 8 | 7,04 |
| 6 | 7,24 | 6 | 6,13 | 6 | 6,08 | 8 | 5,25 |
| 4 | 4,26 | 4 | 3,1 | 4 | 5,39 | 19 | 12,5 |
| 12 | 10,84 | 12 | 9,13 | 12 | 8,15 | 8 | 5,56 |
| 7 | 4,82 | 7 | 7,26 | 7 | 6,42 | 8 | 7,91 |
| 5 | 5,68 | 5 | 4,74 | 5 | 5,73 | 8 | 6,89 |
Antal observationer (n)=11
Medelvärde för x=9
Medelvärde för y=7,5
Standardavvikelse för x=3,32
Standardavvikelse för y=2,03
Och en enkel regressionsmodell (OLS) ger y=3+0,5x med ett p-värde för koefficienten för x på 0,03 och ett R2 som uppgår till 0,67.
Det intressanta är att exakt samma värden även gäller för dataset 2, 3 och 4. Så om vi bara använder dessa standardmått kan vi lätt frestas att dra slutsatsen att sambandet mellan x och y ser ut på samma sätt i de fyra datamaterialen. Stämmer då inte det? Nej, om vi grafiskt illustrerar sambandet mellan x och y i dataseten med hjälp av punktdiagram och en regressionlinje ser vi att det är stora skillnader mellan dem.
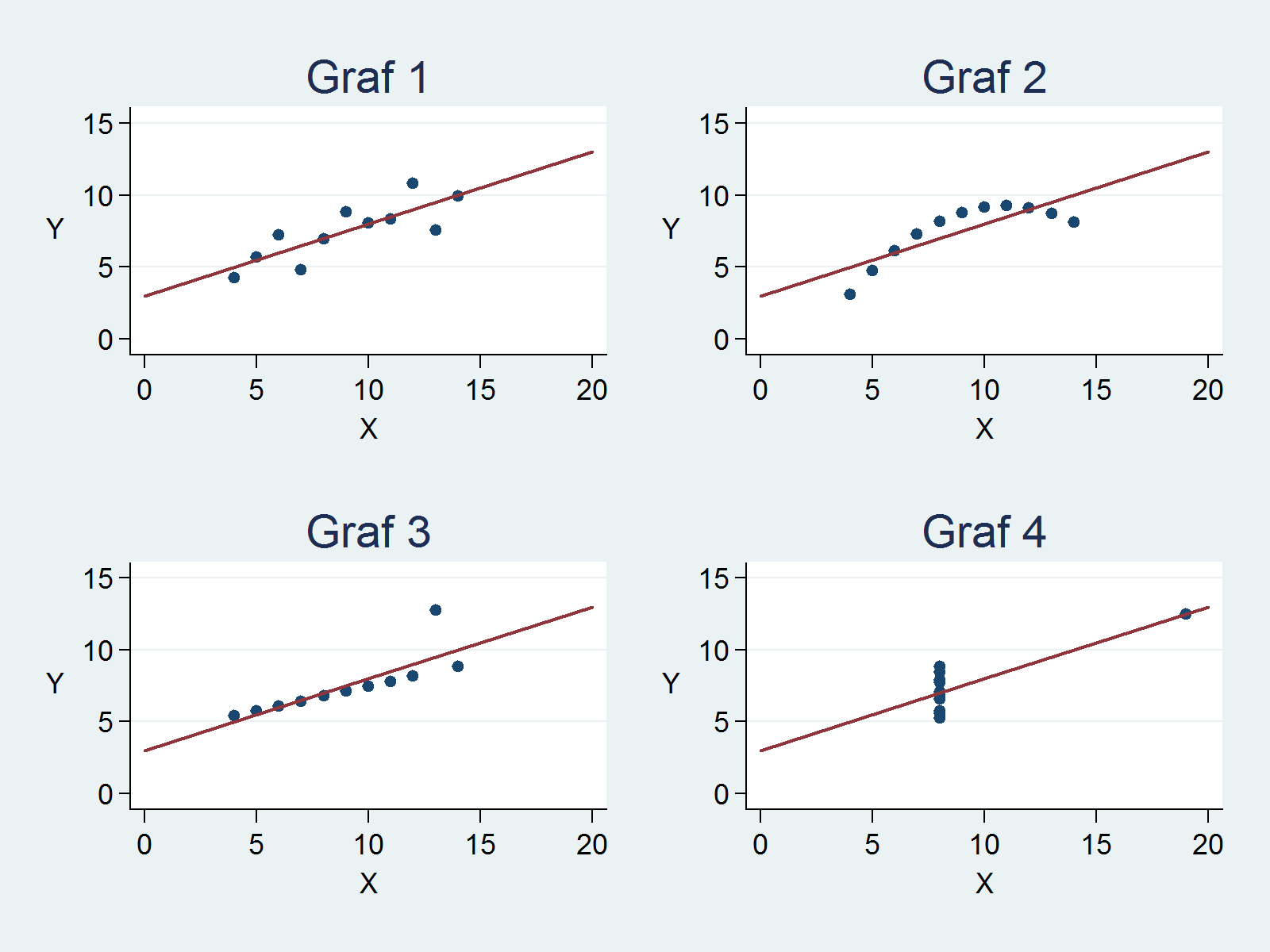
I dataset 1 verkar sambandet mellan x och y vara linjärt och regressionsmodellen förefaller därmed vara lämplig. Punkterna ligger jämnt spridda kring regressionslinjen. Som framgår av graf 2 är den linjära regressionsmodellen däremot inte lämplig för dataset 2. Där verkar istället sambandet mellan x och y vara kurvlinjärt och en modell med en andragradspolynom hade antagligen varit mer lämplig. I dataset 3 verkar visserligen sambandet mellan x och y vara linjärt, men en observation verkar vara en så kallad uteliggare (outlier) och den observationen gör att regressionslinjen blir brantare än den annars skulle vara. Här bör den observationen kontrolleras för att se att det inte är något fel i datamaterialet. Även om datapunkten visar sig vara korrekt kan det finnas anledning att fundera på att utesluta den från modellen (det beror på sammanhanget) eller berätta om dess effekt i presentationen av analysen. I dataset 4 beror sambandet på endast en datapunkt. Om den utesluts finns inte längre något linjärt samband. Även här finns det anledning att studera datamaterialet närmare för att se om ett linjärt samband verkligen finns.
Även om dessa dataset är illustrerar extremfall är det inte ovanligt att motsvarande situationer kan uppstå, om än vanligtvis i lindrigare former. Så slutsatsen är glasklar: visualisera dina data!